Grafo di un sito internet: un esempio in Python
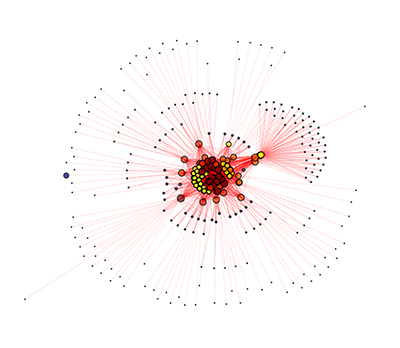
 Grafo di un sito internet: di cosa si tratta?
Grafo di un sito internet: di cosa si tratta?
Tutte le tecnologie, anche quelle di uso quotidiano, hanno alla base un modello matematico ed algoritmi di supporto alla loro implementazione e non sono da meno le tecnologie web. Un esempio classico è il modello linguistico utilizzato nella ricerca semantica da Google e l’algoritmo di stemming per il filtraggio delle stopwords.
Un modello molto più ampio che viene utilizzato da molte tecnologie web è quello basato sui Grafi. Avete mai sentito parlare di Knowledge Graph di Google? O di grafo sociale (o rete sociale) riferito ai social network come Facebook e Linkedin?
Modelli basati sulla teoria dei grafi aiutano a stabilire a rigore le varie connessioni che vi sono tra oggetti o soggetti, stabilendone anche un grado di connessione (o un peso, un’importanza) nell’intero contesto in esame.
Google valuta il nostro sito internet facendo anche delle analisi di questo tipo: vede il nostro sito come un grafo e in buona sostanza stabilisce:
- quali sono le connessioni interne (i link interni alle nostre pagine) e quali sono quelle che hanno più valore;
- quali sono le connessioni con l’esterno e dandoci un punteggio anche in base al ranking dei siti a cui puntiamo (rilevante principalmente per i post nei quali documentiamo con link esterni di qualità).
MA COS’È UN GRAFO?
Un grafo è una struttura matematica discreta le cui proprietà sono definite dalla Teoria dei Grafi. Non è da confondere con il grafico, che non è altro che una rappresentazione grafica di qualcosa, incluso un grafo.
I grafi vengono utilizzati in diverse branche della scienza e della tecnologia, come in biochimica, nello studio delle interazioni in teoria quantistica dei campi, nello studio delle reti informatiche, nello studio delle topologie nei database geografici e, tra le altre infinità numerabili di cose, anche nel web, in particolare nei social network come Facebook e Linkedin e nel modello di Google per il suo motore di ricerca.
GRAFO DI UN SITO: PERCHÉ È IMPORTANTE
Come detto all’inizio dell’articolo, conoscere il grafo di un sito internet ci aiuta a capire come esso è strutturato, ci indica quali sono le pagine con più valore e di conseguenza ci aiuta a capire quali strategie SEO utilizzare. Ad esempio, possiamo scoprire che la pagina “chi sono” è quella che ha più valore nel nostro sito. Cosa facciamo? Cerchiamo di adottare soluzioni che diano più importanza ad un’altra pagina? o sfruttiamo questa? Ma un’altra informazione che può darci la struttura a grafo di un sito internet è la bontà delle connessioni tra le varie pagine interne.
FACCIAMO UN ESEMPIO CON UN’ANALOGIA
Consideriamo tre stazioni ferroviarie: Milano, Bologna, Bari.
La rete ferroviaria che le collega è rappresentata da una linea spezzata: ogni tratto (ogni segmento o arco) unisce due punti, chiamati nodi. Questi nodi non sono altro che le stazioni intermedie, tra cui le stazioni di Milano, Bologna e Bari sono dei nodi.
Bari è un nodo che avrà le sue diramazioni verso tratte regionali e nazionali. Idem Bologna e Milano. Ma le tre stazioni sono importanti in egual misura? Ovviamente la risposta è no!
Bologna è un importante snodo fra tratte nazionali: se da Bari voglio arrivare a Milano devo passare per la stazione di Bologna, che è quindi più importante della stazione di Bari.
Bologna è quindi un nodo più importante rispetto al nodo Bari.
Milano ha un’importanza ancora maggiore perché è uno snodo verso tratte estere.
Per valutare l’importanza di una stazione ci chiediamo quindi:
- quali sono gli snodi regionali?
- quali gli snodi nazionali?
- quali quelli esteri?
Analogamente, la stessa cosa vale per il nostro sito.
- Quali sono le connessioni interne del sito? (le connessioni regionali, in analogia con la rete ferroviaria)
- Quali sono le connessioni esterne del sito, ossia verso siti esterni? (connessioni nazionali e internazionali)
- Quali sono i nodi (siti) interni più importanti?
- Quanto sono importanti i nodi (siti) esterni a cui mi collego? Sono tanti?
Ora è più chiara l’importanza della valutazione del grafo di un sito internet.
ANDIAMO NEL DETTAGLIO
Un articolo bellissimo di Enrico Altavilla, spiega come calcolare la distribuzione del PageRank, mostrando come alla base di questa valutazione vi sia la la struttura a grafo di un sito internet. Nell’articolo inoltre viene spiegata l’utilità di questo tipo di analisi, soprattutto a livello SEO, descrivendo una procedura non tanto complessa.
Le procedure di analisi sono complesse e per spiegarne il senso spesso si cerca di semplificare, cosa che farò nel seguito dell’articolo. Tuttavia è una buona base per approfondire il tema in futuro. Lo scopo in questo articolo è mostrare una semplificazione della procedura di Enrico Altavilla tramite un mio codice scritto in linguaggio Python, molto semplificato e che va ottimizzato in alcuni aspetti tecnici e numerici.
- Estrarre tutti i link interni ed esterni di un sito
- Creare il grafo di un sito: una serie di nodi e archi dove:
- i nodi sono i link del sito
- gli archi sono le connessioni di ogni link interno con tutti gli altri link
- Calcolare qualcosa simile al PageRank, chiamato Eigenvector Centrality, per ogni risorsa del sito
- Creare una rappresentazione grafica del grafo.
L’analisi andrebbe fatta nel dettaglio, valutando link con tag nofollow, valutazione dei link esterni, ed eventuali filtraggi e calcoli: mi riprometto di riaggiornare l’articolo non appena ne avrò l’occasione.
COSA CI SERVE
- Python, scaricabile dal sito ufficiale, o anche da terminale per utenti Linux e MacOSX.
- Le librerie numpy, scipy, matplotlib, networkx, da installare seguendo l’ordine che vi ho elencato!
- La libreria beautiful soup, meravigliosa per gestire i contenuti di file html (parsing HTML).
IL CODICE IN PYTHON PER VALUTARE IL GRAFO DI UN SITO INTERNET
(il codice completo lo trovi a fine articolo)
Il codice viene eseguito nel modulo principale: main.
|
1 2 3 |
def main(home, sitemap, siteType): graph, siteLink = getGraph(sitemap, siteType) |
dove la prima riga esegue il parsing della sitemap, fornendo come risultato un dizionario ed una lista, ossia:
- graph, dizionario dove ogni chiave è un url della nostra sitemap e il corrispondente valore è una lista contenente le url collegate ad esso (link interni a cui rimanda).
- siteLink, lista di tutti gli url della sitemap
Questa operazione viene effettuata dal modulo getGraph()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
def getGraph(sitemap, site='wordpress'): """ get a dict from sitemap, to construct nodes and edges """ xml = getChild(sitemap) documents = {} graph0 = {} graph = {} siteLink = [] if site=='wordpress': for x in xml.keys(): for k in xml[x]: graph[k] = getLink(k) siteLink.append(k) print k else: for k in xml: graph[k] = getLink(k) siteLink.append(k) print k return graph, siteLink |
la riga
|
1 |
xml = getChild(sitemap) |
esegue un parsing della sitemap fornita. Successivamente per ogni url della sitemap viene effettuato un parsing html (url k) tramite
|
1 |
graph[k] = getLink(k) |
sfruttando la liberia beautiful soup (bs4). Le funzioni getChild() e getLink() sono esposte a fine articolo
La funzione fa una distinzione tra le sitemap tipiche fornite dal plugin Yoast WordPresse le sitemap fornite da siti implementati in Joomla.
In particolare una sitemap di Yoast è sviluppata come un albero di file xml:
- sitemap_index.xml
-
post-sitemap.xml
- url 1
- url 2
- …
-
page-sitemap.xml
- url 3
- url 4
- …
-
portfolio-sitemap.xml
- …
-
category-sitemap.xml
- …
- e così via…
-
Le sitemap fornite dai componenti per Joomla invece sono del tipo:
- sitemap.xml
- url 1
- url 2
- url 3
- url 4
- ….
Ritorniamo al modulo main. Dopo aver estratto url e link, passiamo a crearci il grafo del sito. Lo facciamo tramite la libreria networkx, importata con l’abbreviazione nx.
|
1 2 3 4 5 |
.... # creo il grafo G = nx.Graph() G.add_nodes_from(generateNodes(graph)) G.add_edges_from(generateEdges(graph)) |
generateNodes() e generateEdges() sono i moduli tramite i quali vengono estratti i nodi e gli archi secondo il formato richiesto da networkx.
Successivamente ci calcoliamo i valori di Eigenvectors Centrality
|
1 2 3 |
... print 'EIGENVECTORS CENTRALITY' ec = nx.eigenvector_centrality(G, max_iter=100) |
quindi scriviamo su file csv sia i valori di Eigenvectors Centrality, sia i gradi di ogni nodo
|
1 2 3 4 5 6 7 8 9 |
fec = open('ec.csv','w') for k in ec.keys(): fec.write(str(k)+';'+str(ec[k])+'\n') fec.close fdeg = open('nodeDegree.csv', 'w') for v in G: fdeg.write(str(v)+';'+str(float(G.degree(v)))+'\n' ) fdeg.close() |
Infine impostiamo i parametri di plottaggio per ottenere una rappresentazione grafica del grafo del sito in esame, salvandola in alta risoluzione su file pdf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
nomeFig = 'grafo.pdf' tipoFig = 'pdf' graph_pos=nx.spring_layout(G, iterations=400, scale=1)#, dim=10000) print 'GRAPG POS' for n in graph_pos: graph_pos[n] = graph_pos[n]*100 nx.draw_networkx_nodes(G,graph_pos,node_size=[float(G.degree(v))*0.3 for v in G], alpha=0.7, node_color=[float(ec[k]) for k in G.nodes(data=False)],with_labels=False) nx.draw_networkx_edges(G,graph_pos,width=0.1,alpha=0.5,edge_color='r', arrows=True) nx.draw_networkx_labels(G, graph_pos,font_size=0,font_family='sans-serif') plt.axis('off') plt.savefig(nomeFig, format=tipoFig, dpi='9000', figsize=(32.000, 32.000)) # save as png plt.show() |
GRAFO DI UN SITO INTERNET: CODICE COMPLETO
NOTA: il codice è molto semplice e l’ho scritto velocemente a titolo di esempio. Tuttavia sono ben accetti suggerimenti!
Lancio del codice (esempio)
|
1 |
python main.py -s http://www.nicolastella.it/sitemap.xml -p http://www.nicolastella.it/ -t wordpress |
File main.py
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 |
import urllib2 import bs4 import numpy as np import requests from lxml import etree import networkx as nx import matplotlib.pyplot as plt from optparse import OptionContainer, OptionParser, OptionGroup, Option def getChild(linkXml): xmlDict = {} sitemapPages = {} r = requests.get(linkXml) root = etree.fromstring(r.content) for sitemap in root: children = sitemap.getchildren() xmlDict[children[0].text] = [] if children[0].text[-3:] == 'xml': rq = requests.get(children[0].text) subXml = etree.fromstring(rq.content) for el in subXml: pgs = el.getchildren() xmlDict[children[0].text].append(pgs[0].text) return xmlDict def getLink(link): connections = [] nodes = [] nodesName = [] beautiful = urllib2.urlopen(link).read() soup = bs4.BeautifulSoup(beautiful) links = soup.findAll('a') for l in links: ln = l.get('href') #cn = l.string #connections.append((cn, ln)) nodes.append(ln) return nodes def generateNodes(graph): """ return a list of nodes """ nodes = graph.keys() return nodes def generateEdges(graph): """ return a list of tuples thath represents edges """ edges = [] for vertex in graph: for neighbour in graph[vertex]: if {neighbour, vertex} not in edges: edges.append((vertex, neighbour)) return edges def getGraph(sitemap, site='wordpress'): """ get a dict from sitemap, to construct nodes and edges """ xml = getChild(sitemap) documents = {} graph0 = {} graph = {} siteLink = [] if site=='wordpress': for x in xml.keys(): for k in xml[x]: graph[k] = getLink(k) siteLink.append(k) print k else: for k in xml: graph[k] = getLink(k) siteLink.append(k) print k return graph, siteLink def main(home, sitemap, siteType): graph, siteLink = getGraph(sitemap, siteType) print 'GRAPH\n\n' #preparo i dati ## TUTTO G = nx.Graph() G.add_nodes_from(generateNodes(graph)) G.add_edges_from(generateEdges(graph)) #eccentricity = nx.eccentricity(G) #pr = nx.pagerank(G) #googleMatrix = nx.google_matrix(G) #print 'ECCENTRICITY' #print eccentricity #print 'PAGE RANK' #print pr #print 'GOOGLE MATRIX' #print googleMatrix print 'EIGENVECTORS CENTRALITY' ec = nx.eigenvector_centrality(G, max_iter=100) fec = open('ec.csv','w') for k in ec.keys(): fec.write(str(k)+';'+str(ec[k])+'\n') fec.close fdeg = open('nodeDegree.csv', 'w') for v in G: fdeg.write(str(v)+';'+str(float(G.degree(v)))+'\n' ) fdeg.close() nomeFig = 'grafo.pdf' tipoFig = 'pdf' graph_pos=nx.spring_layout(G, iterations=400, scale=1)#, dim=10000) print 'GRAPG POS' for n in graph_pos: graph_pos[n] = graph_pos[n]*100 nx.draw_networkx_nodes(G,graph_pos,node_size=[float(G.degree(v))*0.3 for v in G], alpha=0.7, node_color=[float(ec[k]) for k in G.nodes(data=False)],with_labels=False) nx.draw_networkx_edges(G,graph_pos,width=0.1,alpha=0.5,edge_color='r', arrows=True) nx.draw_networkx_labels(G, graph_pos,font_size=0,font_family='sans-serif') plt.axis('off') plt.savefig(nomeFig, format=tipoFig, dpi='9000', figsize=(32.000, 32.000)) # save as png plt.show() if __name__ == "__main__": home = None sitemap = None siteType = None parser = OptionParser(usage="%prog [options]") parser.add_option("-s", "--sitemap_url", action="store", dest="sitemap_url", default=None, help="Complete url of sitemap, with http://") parser.add_option("-p", "--homepage", action="store", dest="homepage", default=None, help="Complete url of homepage with http://") parser.add_option("-t", "--cms_type", action="store", dest="cms_type", default="wordpress", help="CMS Type: joomla or worpress. Default: wordpress") (options, args) = parser.parse_args() if options.sitemap_url == None: print 'You must specify a sitemap url' exit() elif str(options.sitemap_url[-4:]) != '.xml': print "You must specify an xml sitemap" exit() else: sitemap = str(options.sitemap_url) if str(options.homepage) == None: print 'You must specify a url' exit() else: homepage = str(options.homepage) if options.cms_type == None: print 'You must specify a cms type: wordpress or joomla' exit() elif str(options.cms_type) not in ['wordpress','joomla']: print "You must specify one choice between: wordpress, joomla" exit() else: siteType = str(options.cms_type) main(homepage, sitemap, siteType) |


